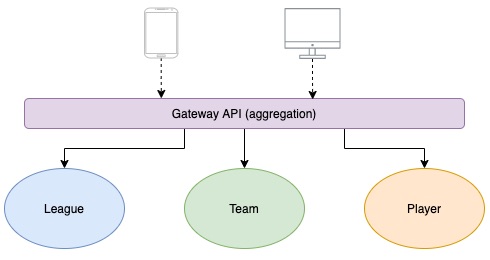
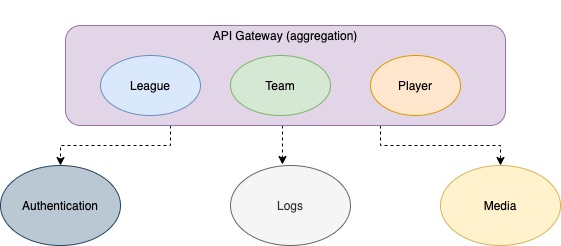
Scalability has become nowadays one of the major problems for any web platform with the expansion of web services users. Having a server down can no longer be tolerated as it results in a bad user experience which leads to several losses, so it is critical for architects and software engineers to conceive a robust and scalable solution in order to handle this expansion in the long run.
Practical case: 3ersi.com
3ersi.com is an algerian web platform that allows you to plan your wedding completely online with the best deals. Whether it is to find a party room, a caterer or even a photographer, you will have the choice between more than 500 providers in more than 100 communes.
3ersi takes the traditional and cultural Algerian marriage to the next level by adding a touch of modernity to it and handling all the organization tasks, leaving you the time to fully appreciate the best moment of your life.
3ersi Media Service
Since the visual can be crucial when choosing any kind of provider for a marriage (Party room, photographer, baker…), 3ersi deals a lot with image files, which increases considerably the amount of requests to the server.
In order to handle this increasing number of requests, Yucca Engineers decided to conceive a media service that will be completely independent of the main 3ersi platform.
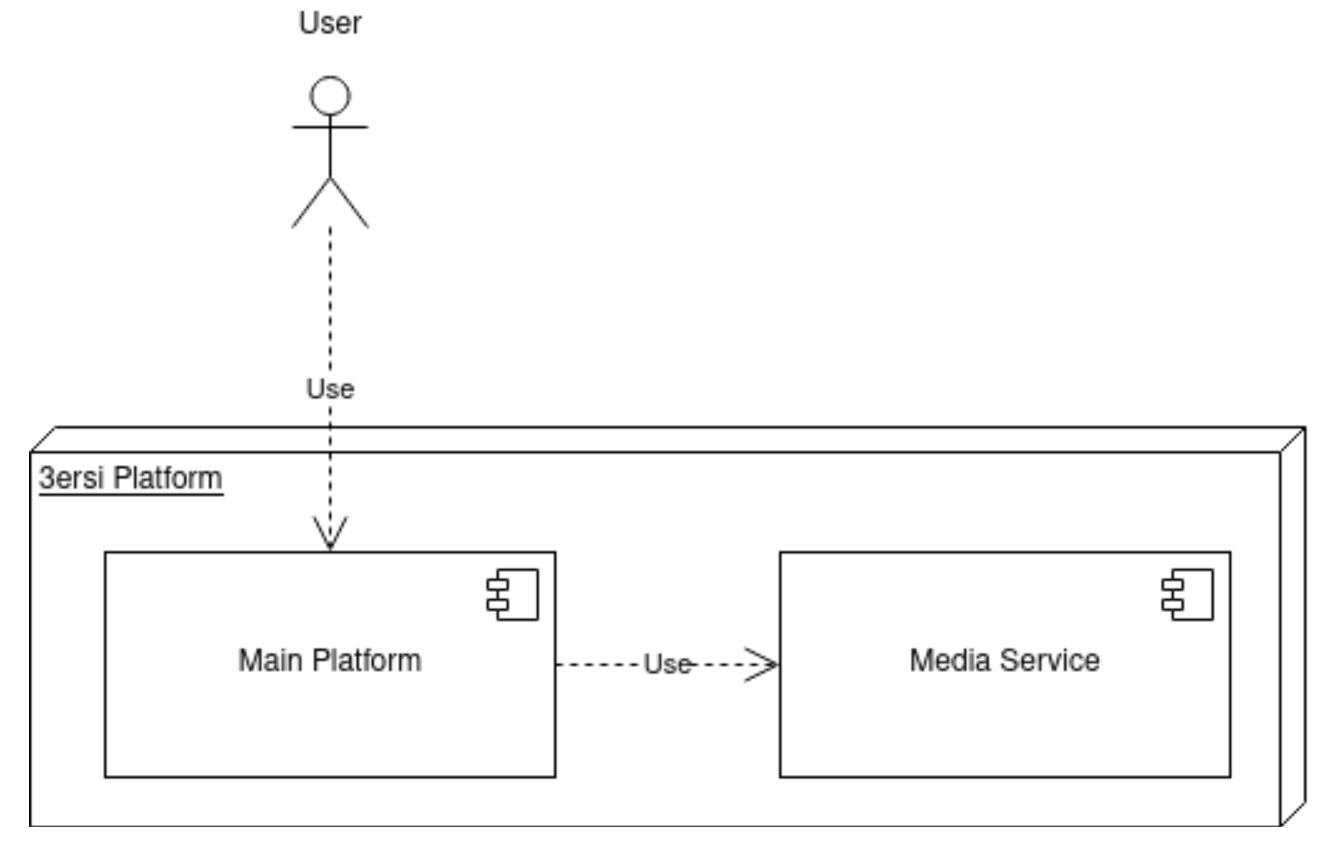
The service will be implemented in its own server with its own endpoints and a dedicated database. The purpose of this is to isolate the image files requests from the main server to reduce its charge, and handle them separately. And since this server will be very requested, Yucca Engineers picked NodeJS to develop it, since it allows a very good use of asynchronous operations, which increases the server’s efficiency.
Problematic
What the 3ersi media service is actually doing is storing upcoming image files to the file system, saving their path and information to the database and serving them when needed.
The problem is that the files were directly stored without further verification, which could lead to storing too large files, or even wrong file types (such as PDF). The files were also stored in a single directory, which can decrease the server’s performances in the long run.
New Media Service
Willing to always improve their solutions for the best, 3ersi engineers decided to look back to their conception, making one foot back and two foot forward, and it was at this moment that I joined the team to help with this task.
Specifications
The new media service needs to cover the shortcomings of the old one, including a solution for a better file management, size and file type verification and scalability improvement.
Approach
In the beginning of the project, we had the idea of storing files directly to the database by converting them into base64 strings, but after trying this technique, we noticed that this solution uses too much ressources, since a converted base64 image has a minimum of 50% raise over its original size, and included more calculation from the server for converting the image to and from base64 when storing/retrieving the image.
So we did more research, and found out that the best solution in our case is to keep storing the image files directly to the file system, but using a hash technique before:
When a file is verified (Size & Type), we use a SHA1 algorithm to hash the file’s name, and add a timestamp to its end to make it unique. Once we did that, we generate a sub-directory of the uploaded images folder using the first two digits of the generated file’s name and store the file in it.
We also thought about a way to compress the files before storing them, and we found the imagemin package that helps with that. Unfortunately, after making performance tests, we noticed that this compression is taking too much ressources, and increased significantly the response time, decreasing by the same way the scalability of the server. So, we decided to leave that task to a cron that will be executed by night and won’t affect the server’s performances.
Finally, we added a new functionality to our server that is meta-data generation, which calculates the image’s dimensions and size in bytes and includes the image’s tags, all bundled in a JSON object that will be stored with the file’s path to the database.
The final diagram of the solution is the following:

Implementation
The new media service will be developed using the hapi framework with NodeJS. For that, we splitted the project into multiple folders, in this article we will focus on the ones that concern the image upload and download:
- config: Contains the server configuration variables, we used environment variables to ensure the server’s security.
- handlers: Contains the different files that will hold the routes handlers.
- helpers: Contains the helpers that will take care of some context-specific function.
- models: Contains the different models that will insure the database interactions.
- routes: Contains the server’s routes.
- upload: Will contain the uploaded files.
First, let’s talk about the upload route. We used to tag, describe and well define our route in order to generate a proper swagger documentation. Then, we managed to limit the image’s size using hapi’s native payload option maxBytes, and turned the payload into a readable stream since we are dealing with files. Finally, the appropriate handler will be called from another file to make it easier to maintain.
That handler will first check the image type before processing it. Once the format is validated, it will proceed to store the file to the server by calling a FileHelper that will generate the new file’s name by hashing it and adding a timestamp to its end, generate the new directory path using the first two file names digits and then send the result in a JSON Object before continuing its task in background to avoid blocking the client more than necessary. Also to enhance the performances, we used streams to store the file to the server.
Once done, the handler will call the Image model to store the image to the database in the background and resolve the client’s request. The Image model will then generate a unique identifier for the image to avoid web scraping and then insert it into the postgresql database.
Each time a user selects a file in the 3ersi platform while fulfilling a form, it’s uploaded to the server. Then we will wait until the user validates his form to continue mapping the image to the user and generate the meta-data. This way the user won’t feel the file’s upload time when validating his form since it’s being uploaded while he is still filling it, which will lead to a better user experience.
Once the form is validated, a new route is addressed to finish the process. This time, the MapHandler will be used to map the image. Mapping an image consists of linking it to its user and storing its meta-data. Since we already know all the files concerned by the form, we will map them all at once: For each file, the Image model will be called in order to map the image in background, and a success message will be sent to the user once the operations are done without errors.
Each file’s meta-data is generated before mapping it in the database. For this purpose, a new helper will be needed, we called it the MetaDataHelper. The image’s dimensions will first be calculated, then its size is added along with its tags to a JSON Object that will represent the image’s meta-data.
Now that we are done with the file upload, let’s take a look at how we send files back to the user. To do that, we made two different routes: One to get an image knowing its id, and another to get it knowing its name.
When the user knows the file’s name, we will use a dedicated route, with a DownloadHandler and simply send it to the client if it exists. If the user doesn’t know the file’s name, we will use this other route to get the image using its id, its handler will then use the id to request the file’s name from the database.
With this, we have fully implemented the core functionalities of our media service. Next, we will proceed to the performance tests.
Performance Measurement
The most important part when conceiving a scalable architecture is to lead performance tests in order to evaluate the server’s limits and breaking points, thus choosing the best hardware configuration.
Approach
We used gatling to do our tests, which is a great tool that uses the potential of Scala to simulate different scenarios and generate a performance report automatically.
Our scenario consists of 5000 users uploading files with a size between 96Kb and 2.6Mb in a period of 60 seconds, 10 seconds, then 5 seconds, for the old and the new media service, and compare their response times and crashing points.
Old Media Service performances
5000 requests within 60 seconds
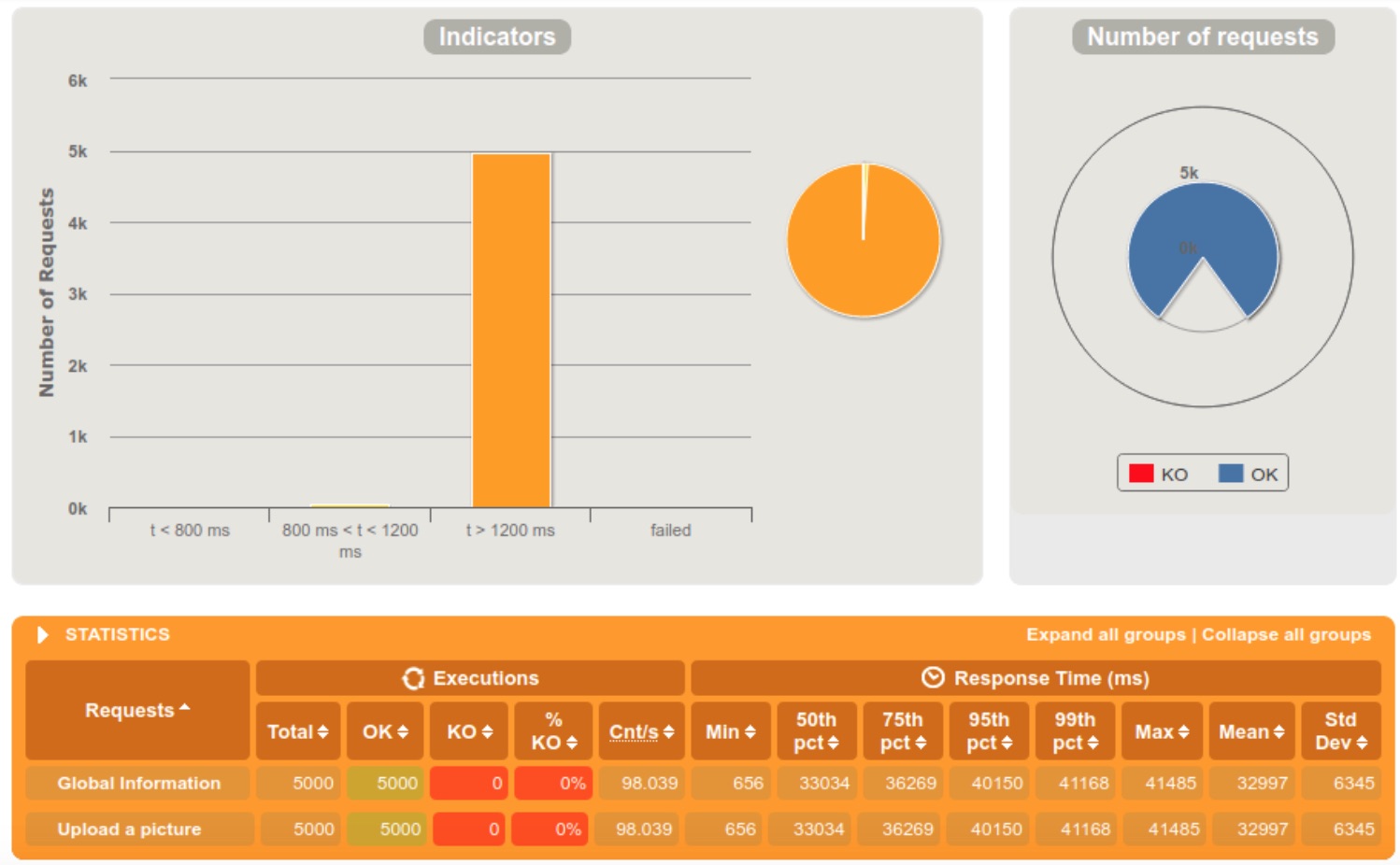
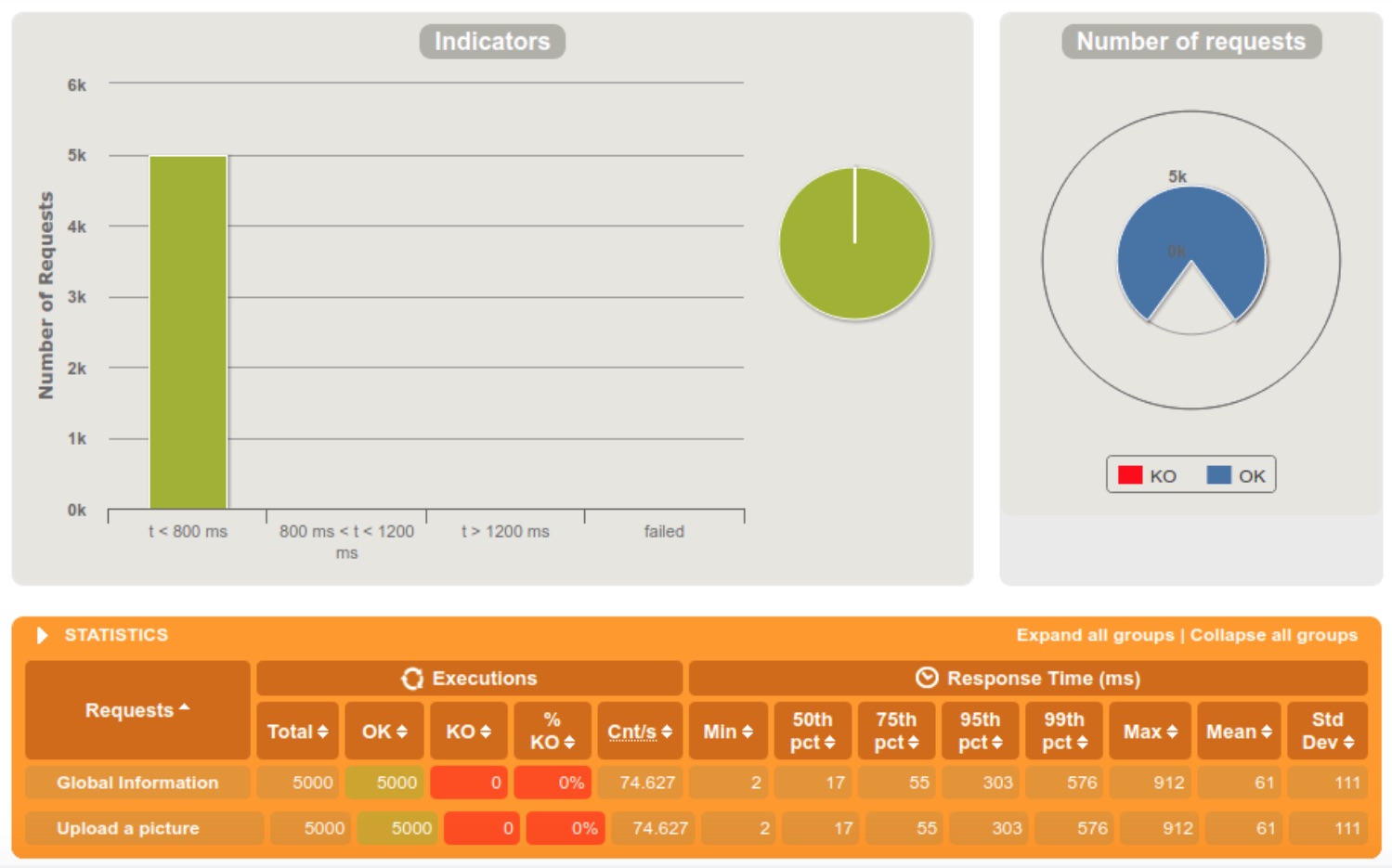
5000 requests within 10 seconds
5000 requests within 5 seconds
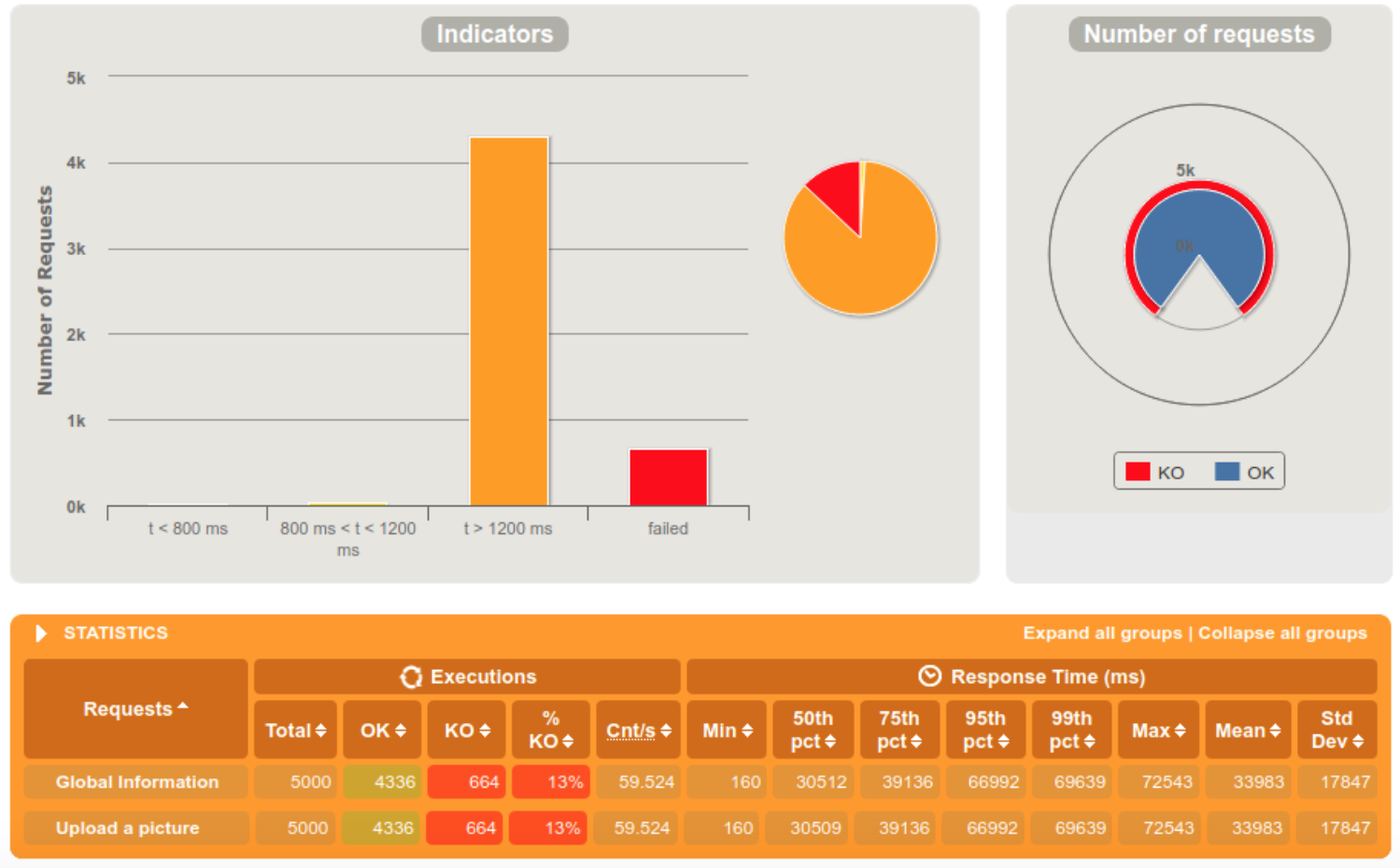
We clearly notice that the server is doing fine when the requests are diffused in a 60 seconds interval, but starts struggling at 10. When we reached the 5 seconds interval, 13% of the requests were rejected because the server crashed.
New Media Service performances
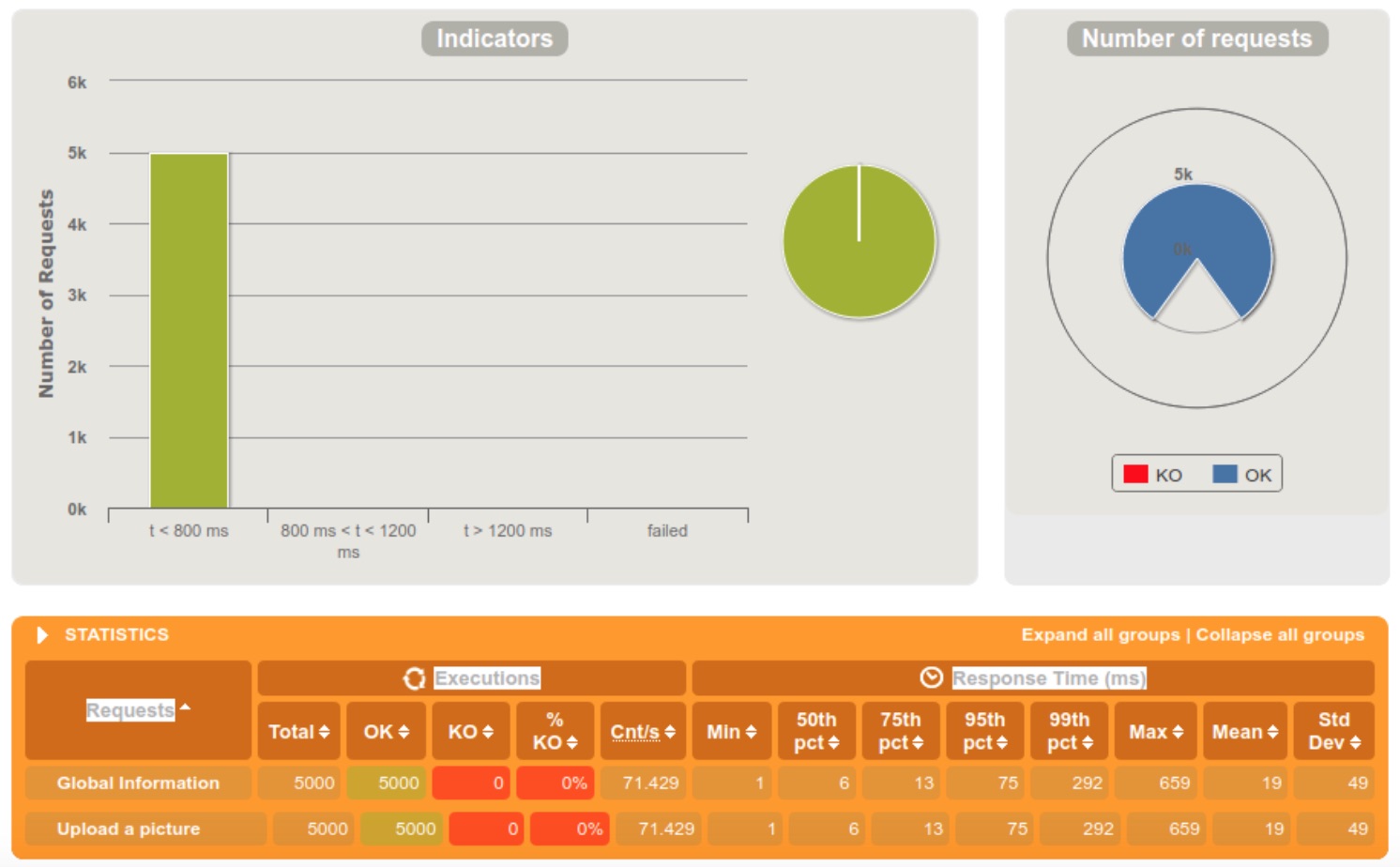
5000 requests within 60 seconds
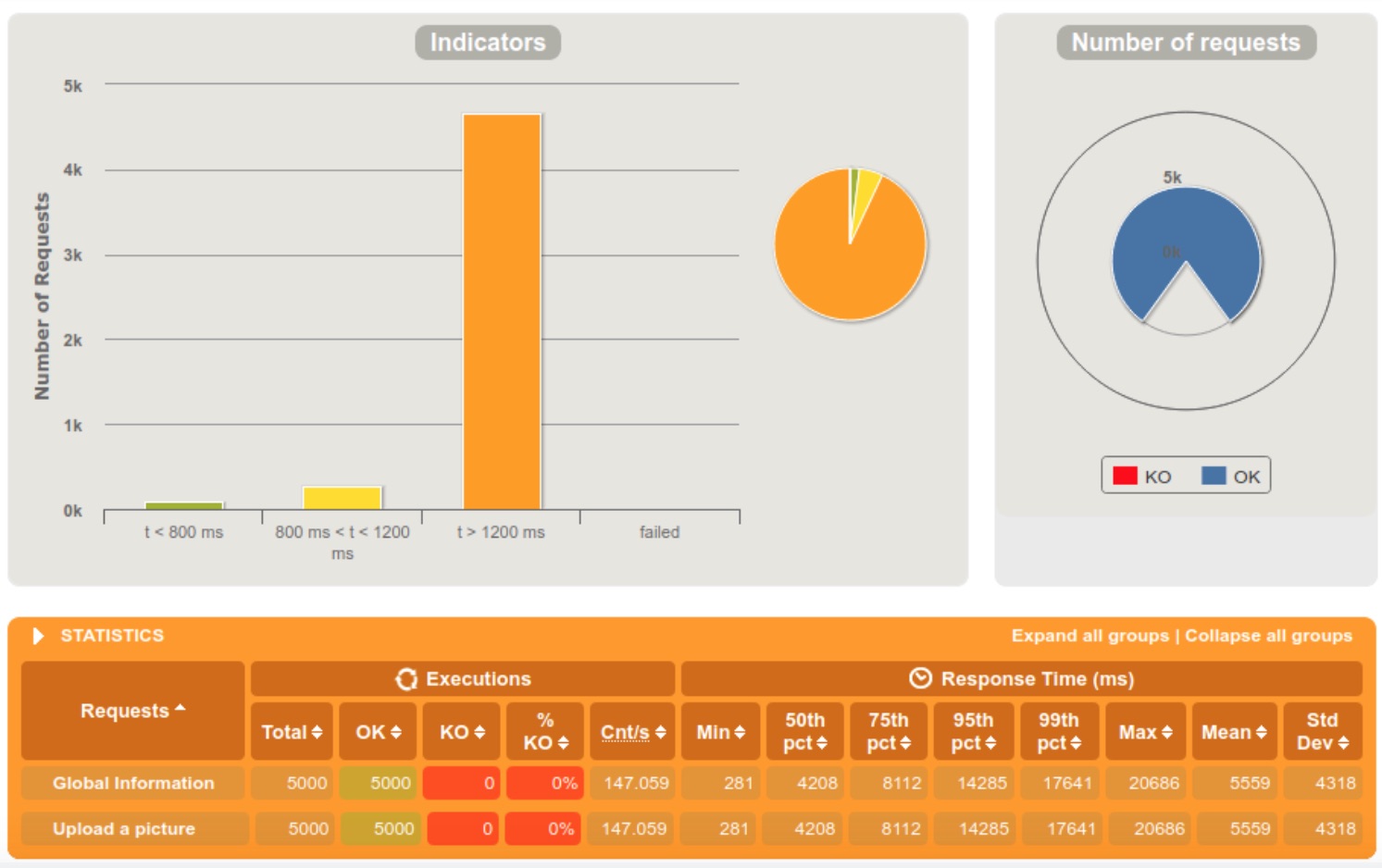
5000 requests within 10 seconds
5000 requests within 5 seconds
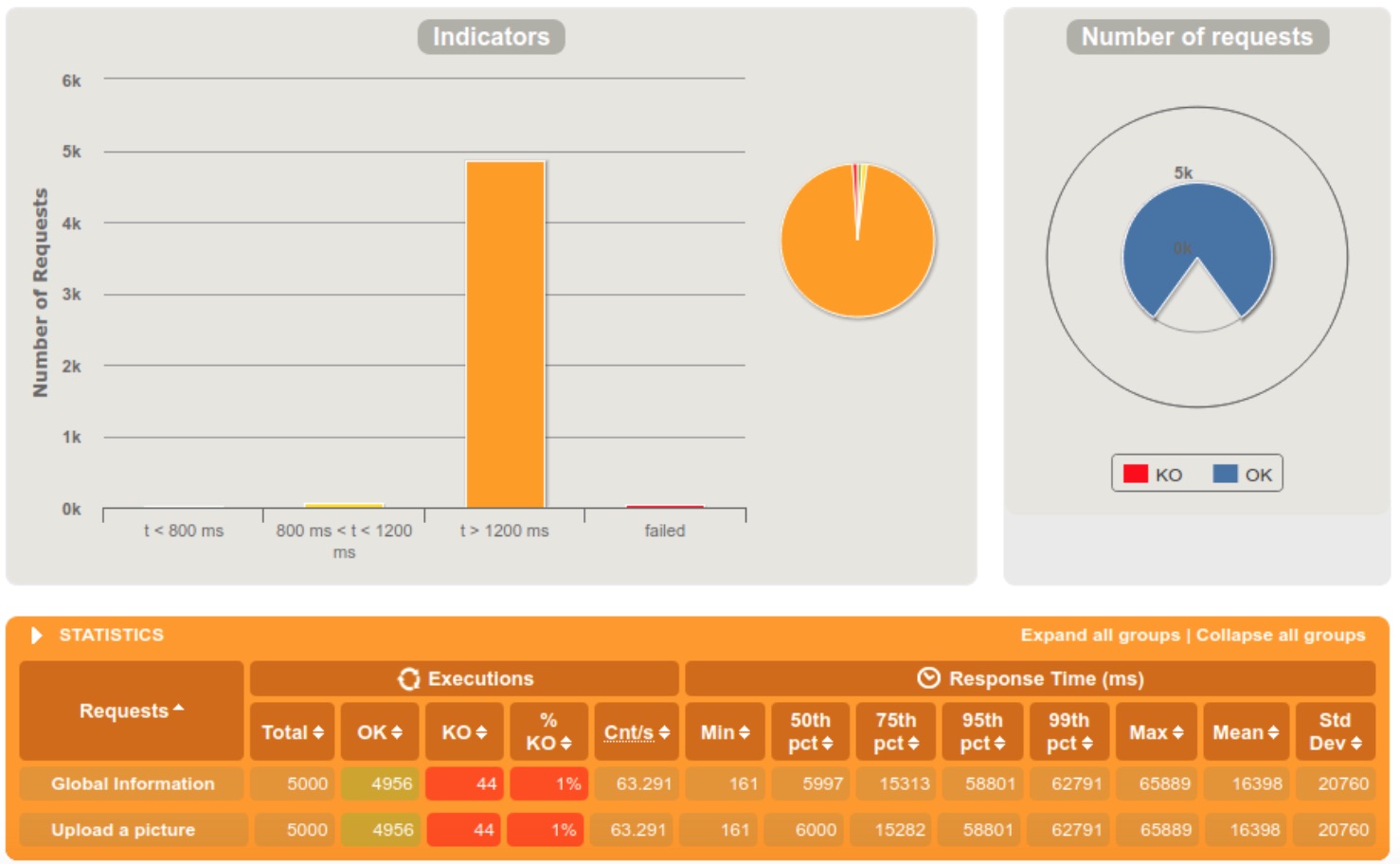
The first thing that we notice is that the new media service has a much better scalability than the old one, rejecting only 1% of the requests when getting 5000 requests within a 5 seconds tight interval. We can also see a big difference in response times between the old and the new media service.
Conclusion
As Albert Einstein said, “Knowledge is Experience”. As Software Engineers, we sure make choices according to what we think is the best solution at the moment, but after experiencing the reality of production, we can spot some points that can be optimized and enhance even more the performances of our solution, so the best way to evolve is to be able to question yourself about your own solutions, and ask “Am i doing it the best way ? “.