I am Akram Bennacer Mohammed, a fourth-year computer science student, specializing in data science and artificial intelligence. I have a keen interest in software engineering and infrastructure and am passionate about sports.
Tell us more about your experience at Yucca Labs ?
Upon joining Yucca Labs with limited experience, my primary goal was to achieve specific goals, and Yucca served as the playground where I discovered myself, particularly in technical aspects. I faced challenges that exceeded my skills at the time, pushing me to grow rapidly.
Through this experience, I realized that working in IT goes beyond coding. It involves business sensitivity, ensuring each team member is in the best position, and understanding the collective effort invested by the team.
What have you learned so far ?
I joined with limited experience and initially focused on simple API methods before delving into more intricate aspects like automated testing. During this journey, I grasped the significance of design patterns, explored domain-driven design, and understood how system designs contribute to delivering efficient and high-quality work.
Being part of a team with diverse expertise, challenges, and goals taught me the importance of effective communication regarding ideas, struggles, and plans. The team rigorously implemented SCRUM, enabling me to function more efficiently and know how my daily actions impacted other team members.
My role primarily involved software engineering and the development of various Yucca applications. However, the collaborative efforts with team members from different domains, such as Tarek, the DevOps specialist, exposed me to new territories I had never explored before.
Can you share with us a big win and a big fail that you experienced at Yucca Labs ?
A significant achievement for me was successfully delivering key components of the web application crucial for strategic purposes, such as the ads system.
On the flip side, a notable setback occurred when I approached development as if all software components were equally important, neglecting to consider the end user and how the task aligned with the overall business schema or plan.
Is it really cool to work for yucca Labs ?
Being a part of Yucca Labs involves embodying the Yucca DNA that Ahmed the CEO keeps mentioning … Having Yucca DNA means being aware and clear about the level of effort required for specific goals, prioritizing a philosophy where victories hold greater significance.
Yucca is characterized by dynamic individuals who strive to be proactive and maintain professionalism in both work and personal life. In essence, being at Yucca is synonymous with living life to the fullest, where diligent work converges with a high-spirited approach.
Your last word …
Yucca was a marking experience for me, not the easiest but definitely one of the most fruitful.
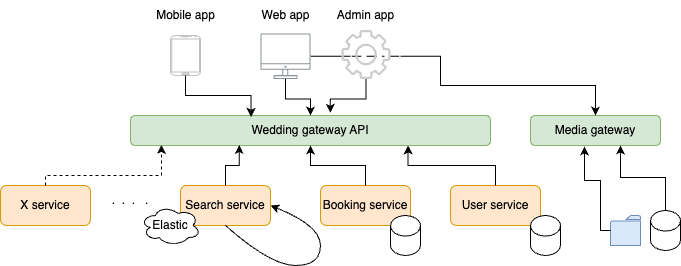
Progressive migration of an Hybrid Micro-services architecture
Four years ago, we embarked on a journey to create a digital platform aimed at assisting individuals in planning their weddings and other special events. . The platform relies on a hybrid micro-services architecture with two gateway APIs built on top of some domain services. The APIs are used to aggregate data and persist users actions. Over time our stack was facing some limitations to let it evolve and match our users growing needs.
The limits we were facing …
We had to upgrade our technologies, using the last LTS versions of our frameworks (Angular, NodeJS, Symfony, …). Most of our used framework were using unsupported versions and was hard to maintain.
We lack confidence when upgrading, the security of preventing regression when developing new features due to an insuffisance test coverage.
Our stack became hard to monitor, we generated millions of logs at every level of our architecture but we were not able to process them properly in oder to build the most relevant operational and security dashbaord that will help us monitor our growth.
We needed to extend our capabilities and provides mobile apps that will ease our users life taking benefit from the push notification system to market our features and implement an instant messaging system.
A new version to shape the future …
We started then migrating and upgrading our services and gateways. The main idea was to break all the limits we were facing. We undertook a bottom/up approach where we braisntormed every service/gateway requirements and designed their new capabilities. The media-service has to strongly validate each media file and compress it when necessary. The search service was then able to automatically reindex updated content and most importantly keep working when indexation is broken… etc
New mobile apps … After progressively migrating our stack from the bottom/up starting from the media and search services and completing it with the client and admin web app through the gateway APIs.
We were then able to easily add mobile methods to our gateway and quickly propose to our users a mobile experience that had strong added value for them (notifications and reminders, instant messaging, … etc)
The actual upgdate also helped us evolve our infrastructure and provides relevant automated processes. Lets see it in detail …
Data Backups: A Seamless and Reliable Approach
Before our platform underwent its transformative migration, our approach to data backups presented a few challenges that demanded innovation and refinement.
The Pre-Migration Challenges
Primarily, backups were conducted manually, introducing a degree of human involvement that could lead to oversights and potential errors. Additionally, the schedule for these backups was inconsistent, as they were not automated. This irregularity meant that certain critical data might not be backed up in time, leaving it vulnerable to potential loss or corruption.
A Transformation in Strategy
To address these vulnerabilities and fortify our data protection strategy, we embarked on a journey of transformation, implementing several crucial changes that reshaped our approach to backups.
1. Automation: A Game-Changer
First and foremost, we automated the backup process, eliminating the manual element. This monumental shift ensured that backups were executed reliably, significantly reducing the margin for human error. The automation also facilitated a regular backup schedule, providing a continuous layer of data protection. This change alone revolutionized the reliability and effectiveness of our backup strategy.
2. Expanding the Horizon of Protection
In addition to automating and regularizing our backup process, we took a more comprehensive approach to safeguarding our data. While previously, the focus was primarily on the database, we broadened our scope to encompass other critical sources of information. This included application-level components such as app logs, as well as system-level information. This holistic approach ensures that a wider array of essential data is safeguarded, contributing to a more robust data protection strategy.
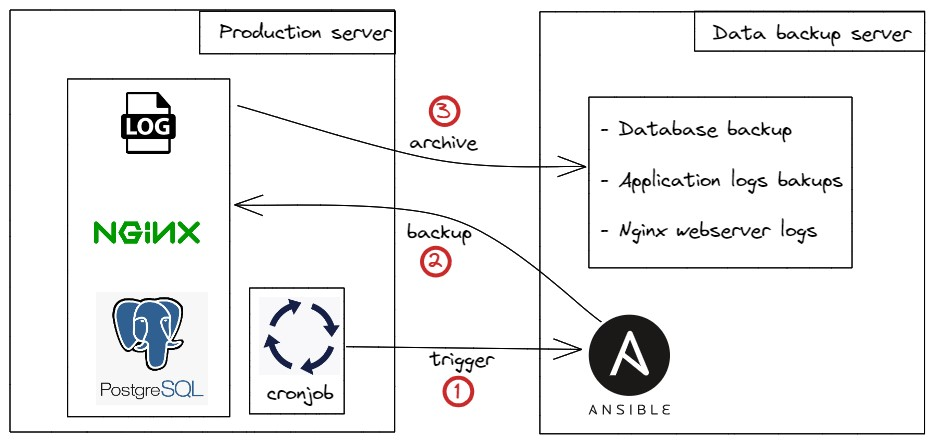
The Power Duo: Cronjobs and Ansible
To achieve this seamless transition and expansion of our backup strategy, we opted for a solution that balanced simplicity with effectiveness. Enter the dynamic duo of Cronjobs and Ansible.
Cronjobs: Precision in Scheduling
Cronjobs, a time-based job scheduler in Unix-like operating systems, emerged as a linchpin in our strategy. This versatile tool allowed us to schedule automated tasks with unparalleled precision. By defining specific time intervals, we ensured that backups occurred consistently and reliably, leaving no room for oversight.
Ansible: Orchestrating Excellence
Complementing Cronjobs, we integrated Ansible, a versatile automation platform that elevated our backup process to new heights. Ansible’s user-friendly playbooks provided a clear and structured way to define backup procedures. Through Ansible, we could orchestrate the entire process, from initiating the backup to ensuring the secure storage of the backed-up data. This synergy between Cronjobs and Ansible streamlined our backup process, ensuring efficiency and reliability.
Embracing Simplicity for Unwavering Security
This combination of Cronjobs and Ansible proved to be a highly effective approach. It allowed us to achieve our backup objectives without the need for intricate or resource-intensive systems. Instead, we harnessed the power of simplicity, ensuring that our data was safeguarded efficiently and consistently.
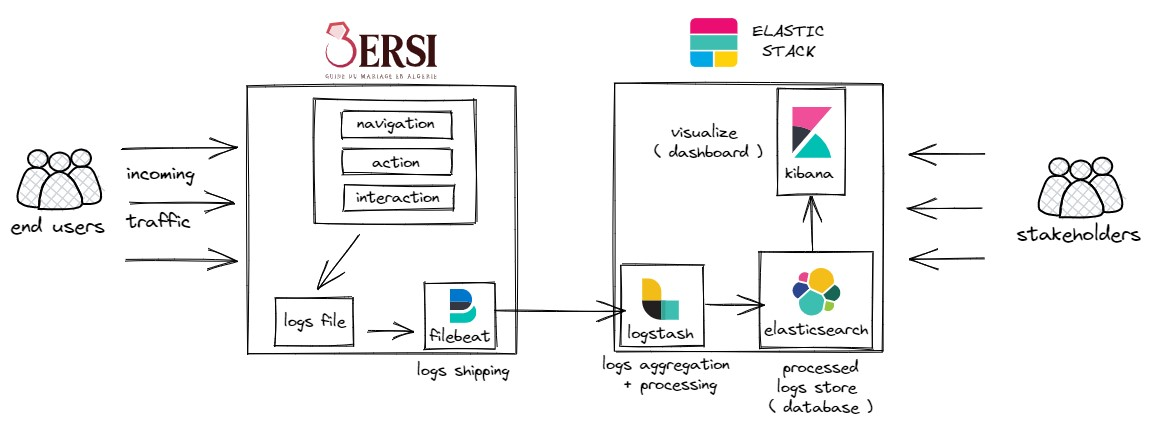
ELK stack (Logstash, Filebeat, Kibana)
Maximizing Website Performance: The Power of Strategic Dashboards
In the realm of multi-user platforms, 3ersi.com stands tall as one of YuccaLabs’ flagship products, drawing a growing traffic, averaging 60K visits per month. This substantial volume speaks volumes about the platform’s popularity and the level of user engagement it commands. With such a dynamic user base, it becomes imperative for stakeholders to possess a crystal-clear understanding of the platform’s performance metrics and the key performance indicators (KPIs) that underlie critical strategic decisions.
The Role of Operational Dashboards
To address this pressing need, we have devised a comprehensive solution centered around strategic and operational dashboards. The operational dashboard serves as the pulse of 3ersi.com, providing real-time insights into its day-to-day performance. This invaluable tool not only informs employees and stakeholders but also forms the base of our operational strategy, facilitating the ongoing monitoring of operational objectives.
Gaining a Strategic Perspective
In contrast, the strategic dashboard offers a bird’s-eye view of the organization’s essential KPIs. This panoramic viewpoint allows us to assess medium-term performance trends, providing invaluable insights that enable us to refine and articulate our strategic objectives. Through this, we are better poised to align our efforts and hit our KPI targets, propelling our commercial strategy forward.
Fusing Data-Driven Decision-Making
In the rapidly evolving landscape of online platforms, staying ahead requires more than just intuition. It demands precision, insight, and the right tools. These dashboards represent a pivotal step in our unwavering commitment to data-driven decision-making. They ensure that our short-term operational goals and long-term strategic objectives remain closely aligned with our overall mission and vision. It’s not just about numbers; it’s about deriving actionable insights that propel us forward.
The ELK Stack: A Powerhouse of Efficiency
To bring these dashboards to life, we harnessed the formidable power of the ELK stack– a seamless integration of Elasticsearch, Logstash, Kibana, and Beats.
1. Elasticsearch: This is where the magic happens. Elasticsearch serves as our search and analytics engine, capable of handling voluminous data. It enables us to swiftly find and analyze the information we need.
2. Logstash: Think of Logstash as our data processor. It assimilates diverse data types from various sources, processes them, and prepares them for indexing in Elasticsearch. This step is vital in ensuring our data is organized and ready for analysis.
3. Kibana: Kibana emerges as our visual storyteller. It’s the tool we wield to craft the dashboards. With Kibana, we seamlessly transform raw data into easily understandable visualizations.
4. Beats: Acting as nimble data shippers, Beats are lightweight agents we deploy on different servers to collect specific types of data. This data is then dispatched to Logstash for processing. Beats ensure that we capture all the pertinent information required.
Through the ELK stack, we’ve erected a robust data pipeline. It empowers us to collect, parse, index, and visualize data with utmost efficiency and seamlessness. We’re not merely accumulating information; we’re making it accessible and comprehensible for everyone involved.
The staging environement
Optimizing Infrastructure for Seamless Operations
Before embarking on the progressive migration, our platform faced a series of significant challenges that demanded our attention and strategic intervention.
The Initial Challenges
At the outset, our operations were primarily confined to a production environment. This limited our capacity to conduct comprehensive tests, which were carried out manually. This manual testing process, while indispensable, was labor-intensive and inherently susceptible to human error. Automation was, regrettably, at a minimum, with only basic deployment scripts in place.
A Shift: Comprehensive Infrastructure Overhaul
Recognizing the critical need for a transformation, we embarked on a comprehensive overhaul of our infrastructure. The changes introduced were both substantial and transformative in nature.
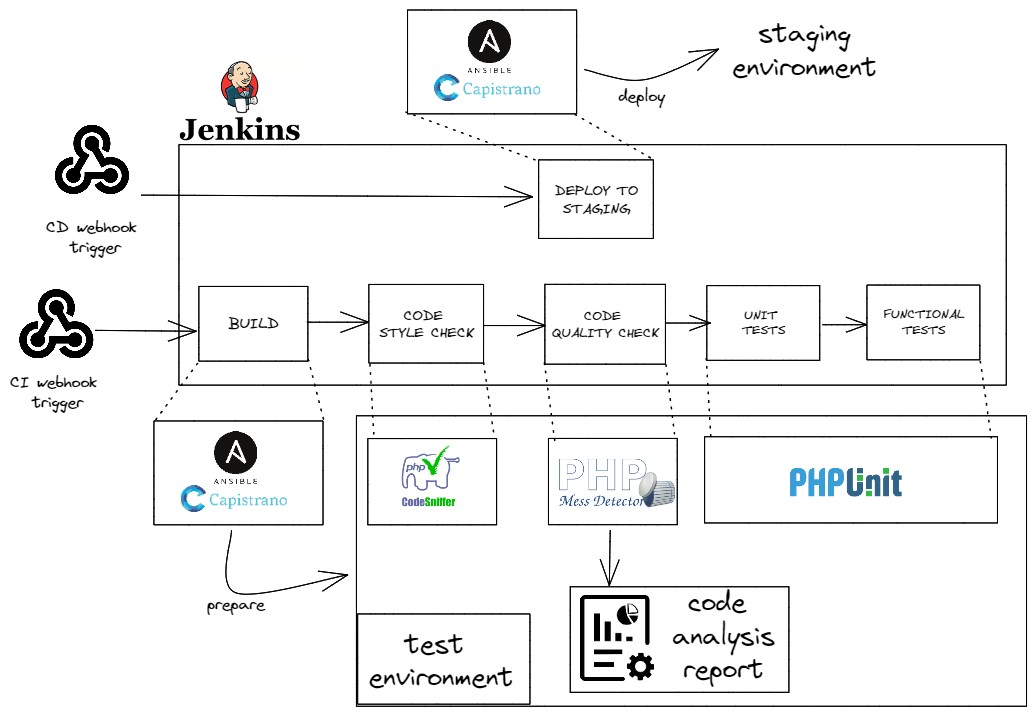
Introducing Automated Testing Environments
One of the important improvements was the introduction of specific automated testing environments. This marked a significant change in our testing approach. Every aspect of our system underwent thorough examination before deployment. This change not only ensured the identification of possible weaknesses but also strengthened the overall reliability and stability of our platform.”
The Staging Environment: Ensuring Clean Deployment
In parallel, we introduced a staging environment, where every component of our platform was carefully examined before being deployed into the live environment. This additional layer of examination was instrumental in guaranteeing the seamless operation of our platform, free from potential hiccups or glitches.
Automation with CI/CD Pipeline
Automation, undoubtedly, emerged as a key element of our infrastructure enhancement strategy. We instituted a robust Continuous Integration/Continuous Deployment (CI/CD) pipeline, a dynamic framework that revolutionized our development process.
Prioritizing Quality at Every Stage
This pipeline is characterized by multiple stages, each designed to prioritize quality at every step. From code integration to deployment, quality assurance is embedded into the very fabric of our development process. This dynamic approach not only accelerates our workflows but also equips us to respond more effectively to evolving requirements.
Conclusion
After 8 months of rethinking our architecture and rewriting each brick we ended up with an IT stack that is helping us move faster in the market and ease our life to evolve it and most importantly is changing our users perception of the products we’re providing.
We thank all those who participating in our engineering team making the dream became a reality: Amine Benbakhta, Mohammed Bounoua, Tarek Mohamed Hacene, Yasser Belatreche, Mohammed Tirichine, Akram Mohammed Bennacer and Ahmed SIOUANI.
Scalability has become nowadays one of the major problems for any web platform with the expansion of web services users. Having a server down can no longer be tolerated as it results in a bad user experience which leads to several losses, so it is critical for architects and software engineers to conceive a robust and scalable solution in order to handle this expansion in the long run.
Practical case: 3ersi.com
3ersi.com is an algerian web platform that allows you to plan your wedding completely online with the best deals. Whether it is to find a party room, a caterer or even a photographer, you will have the choice between more than 500 providers in more than 100 communes.
3ersi takes the traditional and cultural Algerian marriage to the next level by adding a touch of modernity to it and handling all the organization tasks, leaving you the time to fully appreciate the best moment of your life.
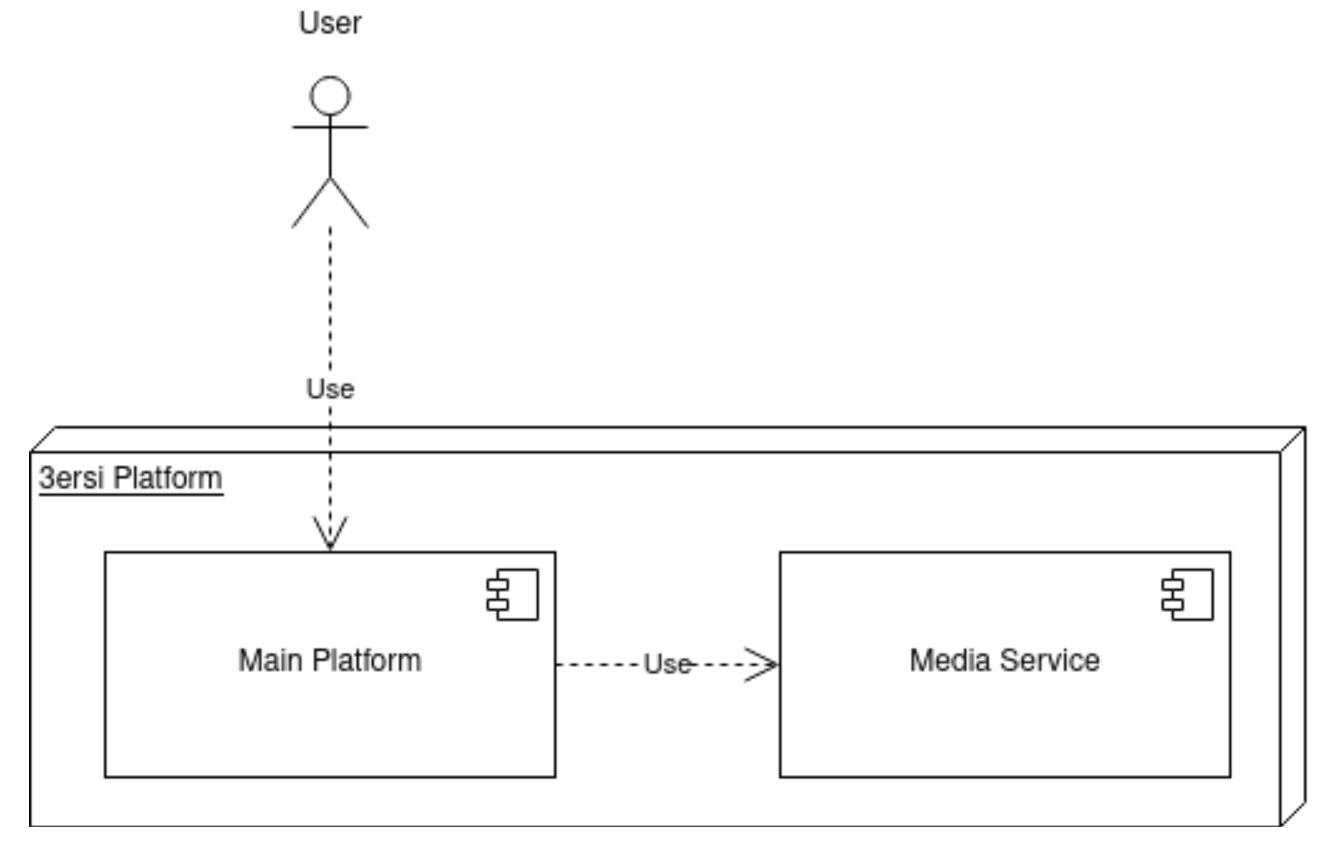
3ersi Media Service
Since the visual can be crucial when choosing any kind of provider for a marriage (Party room, photographer, baker…), 3ersi deals a lot with image files, which increases considerably the amount of requests to the server.
In order to handle this increasing number of requests, Yucca Engineers decided to conceive a media service that will be completely independent of the main 3ersi platform.
The service will be implemented in its own server with its own endpoints and a dedicated database. The purpose of this is to isolate the image files requests from the main server to reduce its charge, and handle them separately. And since this server will be very requested, Yucca Engineers picked NodeJS to develop it, since it allows a very good use of asynchronous operations, which increases the server’s efficiency.
Problematic
What the 3ersi media service is actually doing is storing upcoming image files to the file system, saving their path and information to the database and serving them when needed.
The problem is that the files were directly stored without further verification, which could lead to storing too large files, or even wrong file types (such as PDF). The files were also stored in a single directory, which can decrease the server’s performances in the long run.
New Media Service
Willing to always improve their solutions for the best, 3ersi engineers decided to look back to their conception, making one foot back and two foot forward, and it was at this moment that I joined the team to help with this task.
Specifications
The new media service needs to cover the shortcomings of the old one, including a solution for a better file management, size and file type verification and scalability improvement.
Approach
In the beginning of the project, we had the idea of storing files directly to the database by converting them into base64 strings, but after trying this technique, we noticed that this solution uses too much ressources, since a converted base64 image has a minimum of 50% raise over its original size, and included more calculation from the server for converting the image to and from base64 when storing/retrieving the image.
So we did more research, and found out that the best solution in our case is to keep storing the image files directly to the file system, but using a hash technique before:
When a file is verified (Size & Type), we use a SHA1 algorithm to hash the file’s name, and add a timestamp to its end to make it unique. Once we did that, we generate a sub-directory of the uploaded images folder using the first two digits of the generated file’s name and store the file in it.
We also thought about a way to compress the files before storing them, and we found the imagemin package that helps with that. Unfortunately, after making performance tests, we noticed that this compression is taking too much ressources, and increased significantly the response time, decreasing by the same way the scalability of the server. So, we decided to leave that task to a cron that will be executed by night and won’t affect the server’s performances.
Finally, we added a new functionality to our server that is meta-data generation, which calculates the image’s dimensions and size in bytes and includes the image’s tags, all bundled in a JSON object that will be stored with the file’s path to the database.
The final diagram of the solution is the following:
Implementation
The new media service will be developed using the hapi framework with NodeJS. For that, we splitted the project into multiple folders, in this article we will focus on the ones that concern the image upload and download:
config: Contains the server configuration variables, we used environment variables to ensure the server’s security.
handlers: Contains the different files that will hold the routes handlers.
helpers: Contains the helpers that will take care of some context-specific function.
models: Contains the different models that will insure the database interactions.
routes: Contains the server’s routes.
upload: Will contain the uploaded files.
First, let’s talk about the upload route. We used to tag, describe and well define our route in order to generate a proper swagger documentation. Then, we managed to limit the image’s size using hapi’s native payload option maxBytes, and turned the payload into a readable stream since we are dealing with files. Finally, the appropriate handler will be called from another file to make it easier to maintain.
That handler will first check the image type before processing it. Once the format is validated, it will proceed to store the file to the server by calling a FileHelper that will generate the new file’s name by hashing it and adding a timestamp to its end, generate the new directory path using the first two file names digits and then send the result in a JSON Object before continuing its task in background to avoid blocking the client more than necessary. Also to enhance the performances, we used streams to store the file to the server.
Once done, the handler will call the Image model to store the image to the database in the background and resolve the client’s request. The Image model will then generate a unique identifier for the image to avoid web scraping and then insert it into the postgresql database.
Each time a user selects a file in the 3ersi platform while fulfilling a form, it’s uploaded to the server. Then we will wait until the user validates his form to continue mapping the image to the user and generate the meta-data. This way the user won’t feel the file’s upload time when validating his form since it’s being uploaded while he is still filling it, which will lead to a better user experience.
Once the form is validated, a new route is addressed to finish the process. This time, the MapHandler will be used to map the image. Mapping an image consists of linking it to its user and storing its meta-data. Since we already know all the files concerned by the form, we will map them all at once: For each file, the Image model will be called in order to map the image in background, and a success message will be sent to the user once the operations are done without errors.
Each file’s meta-data is generated before mapping it in the database. For this purpose, a new helper will be needed, we called it the MetaDataHelper. The image’s dimensions will first be calculated, then its size is added along with its tags to a JSON Object that will represent the image’s meta-data.
Now that we are done with the file upload, let’s take a look at how we send files back to the user. To do that, we made two different routes: One to get an image knowing its id, and another to get it knowing its name.
When the user knows the file’s name, we will use a dedicated route, with a DownloadHandler and simply send it to the client if it exists. If the user doesn’t know the file’s name, we will use this other route to get the image using its id, its handler will then use the id to request the file’s name from the database.
With this, we have fully implemented the core functionalities of our media service. Next, we will proceed to the performance tests.
Performance Measurement
The most important part when conceiving a scalable architecture is to lead performance tests in order to evaluate the server’s limits and breaking points, thus choosing the best hardware configuration.
Approach
We used gatling to do our tests, which is a great tool that uses the potential of Scala to simulate different scenarios and generate a performance report automatically.
Our scenario consists of 5000 users uploading files with a size between 96Kb and 2.6Mb in a period of 60 seconds, 10 seconds, then 5 seconds, for the old and the new media service, and compare their response times and crashing points.
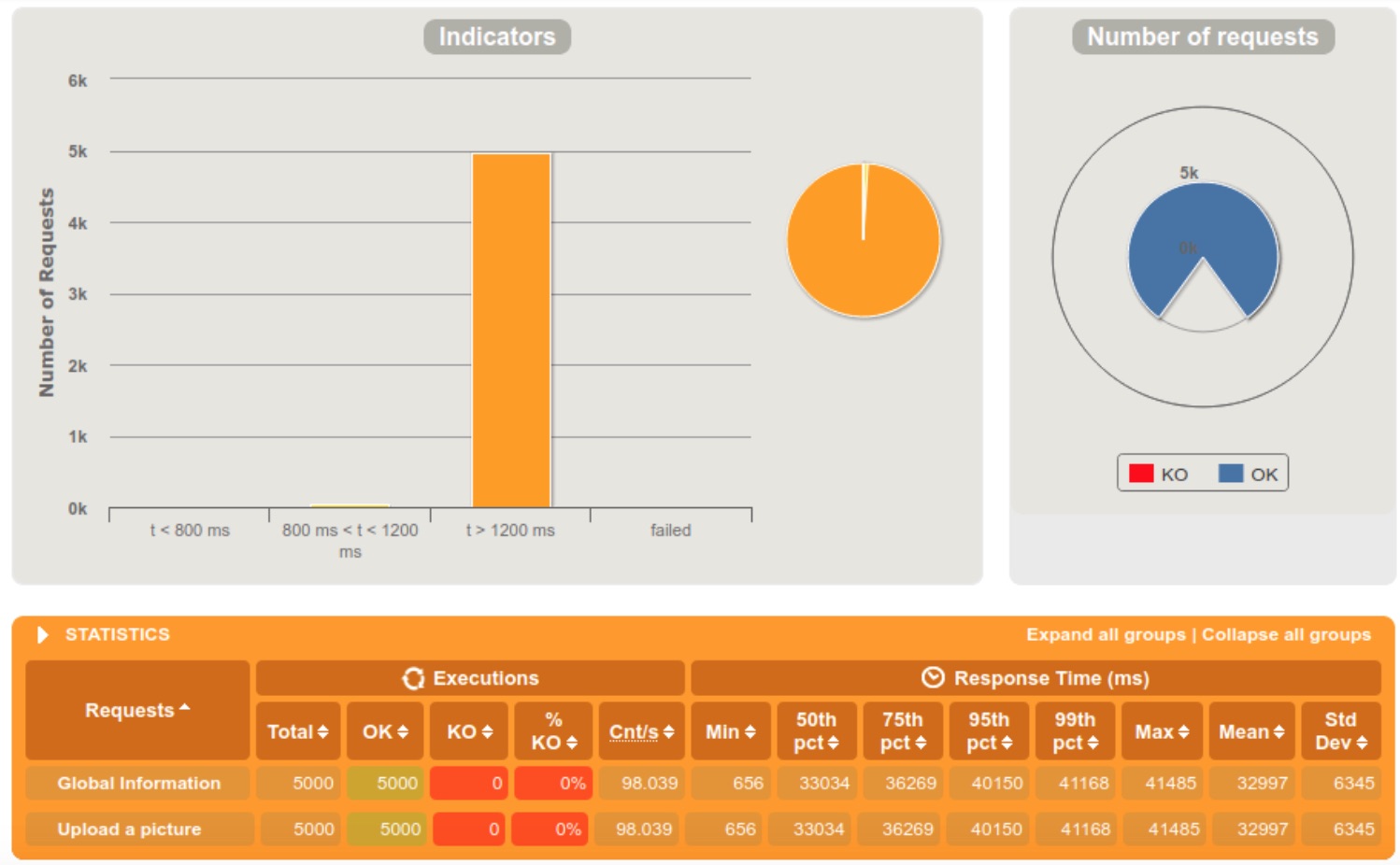
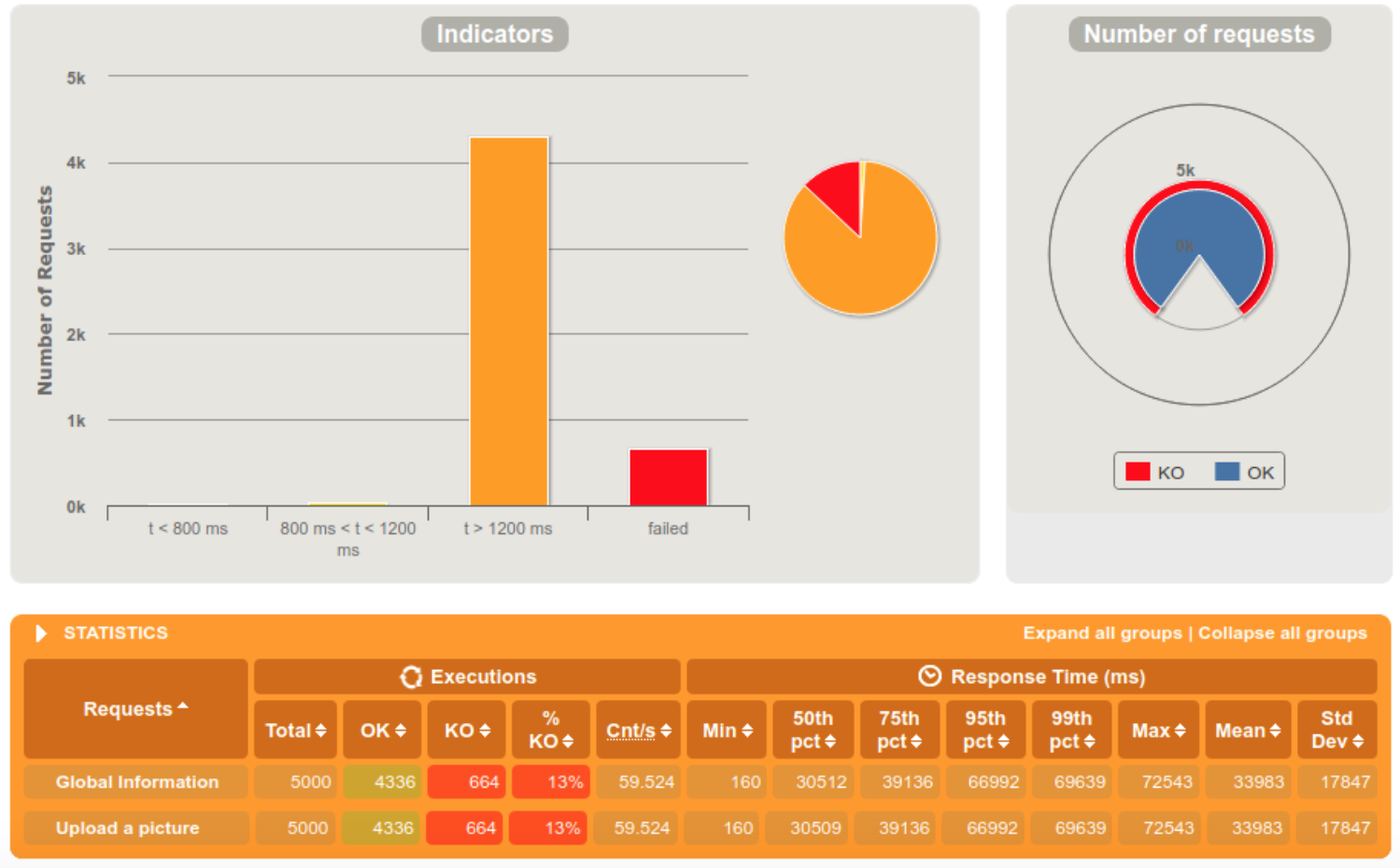
Old Media Service performances
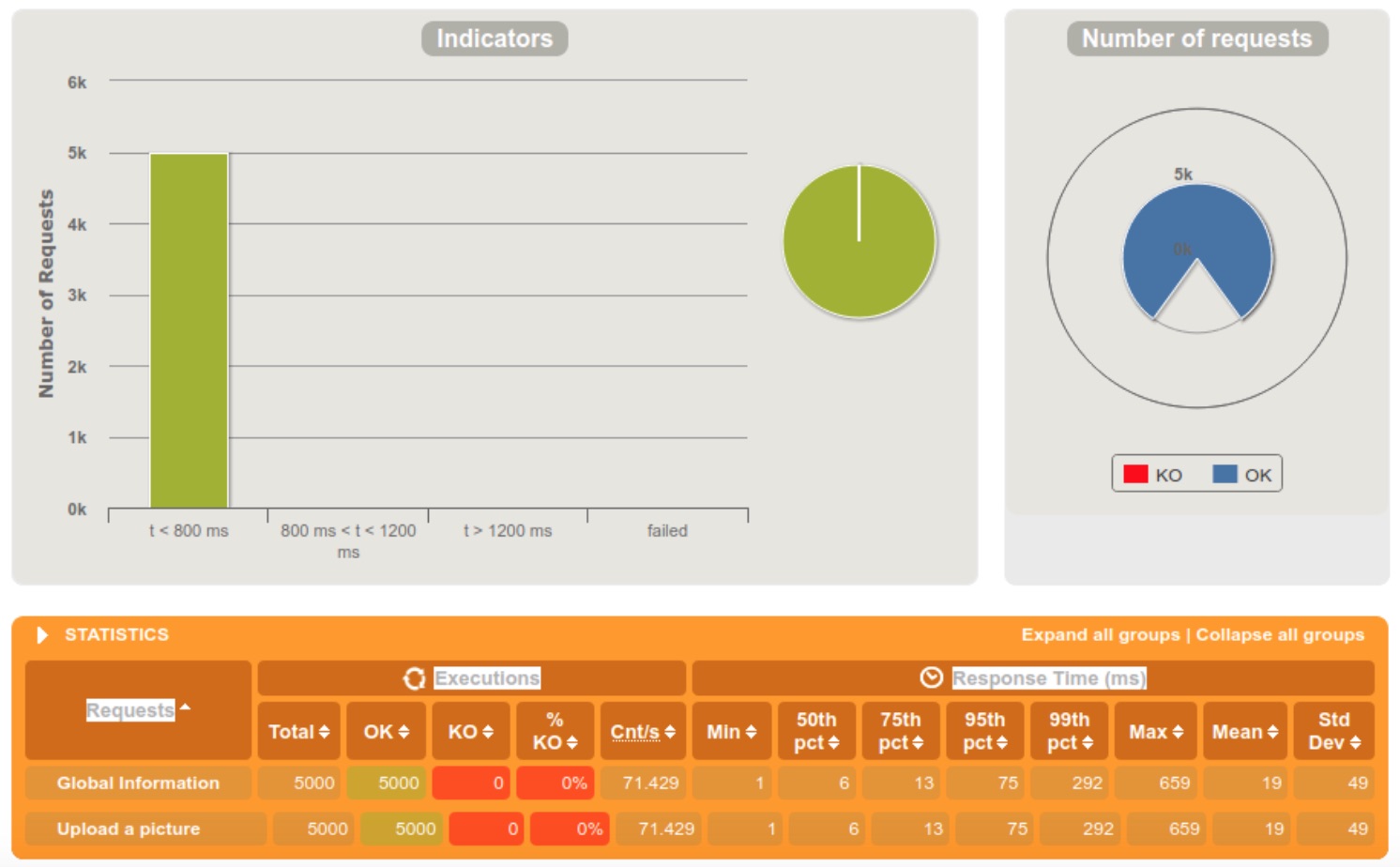
5000 requests within 60 seconds
5000 requests within 10 seconds
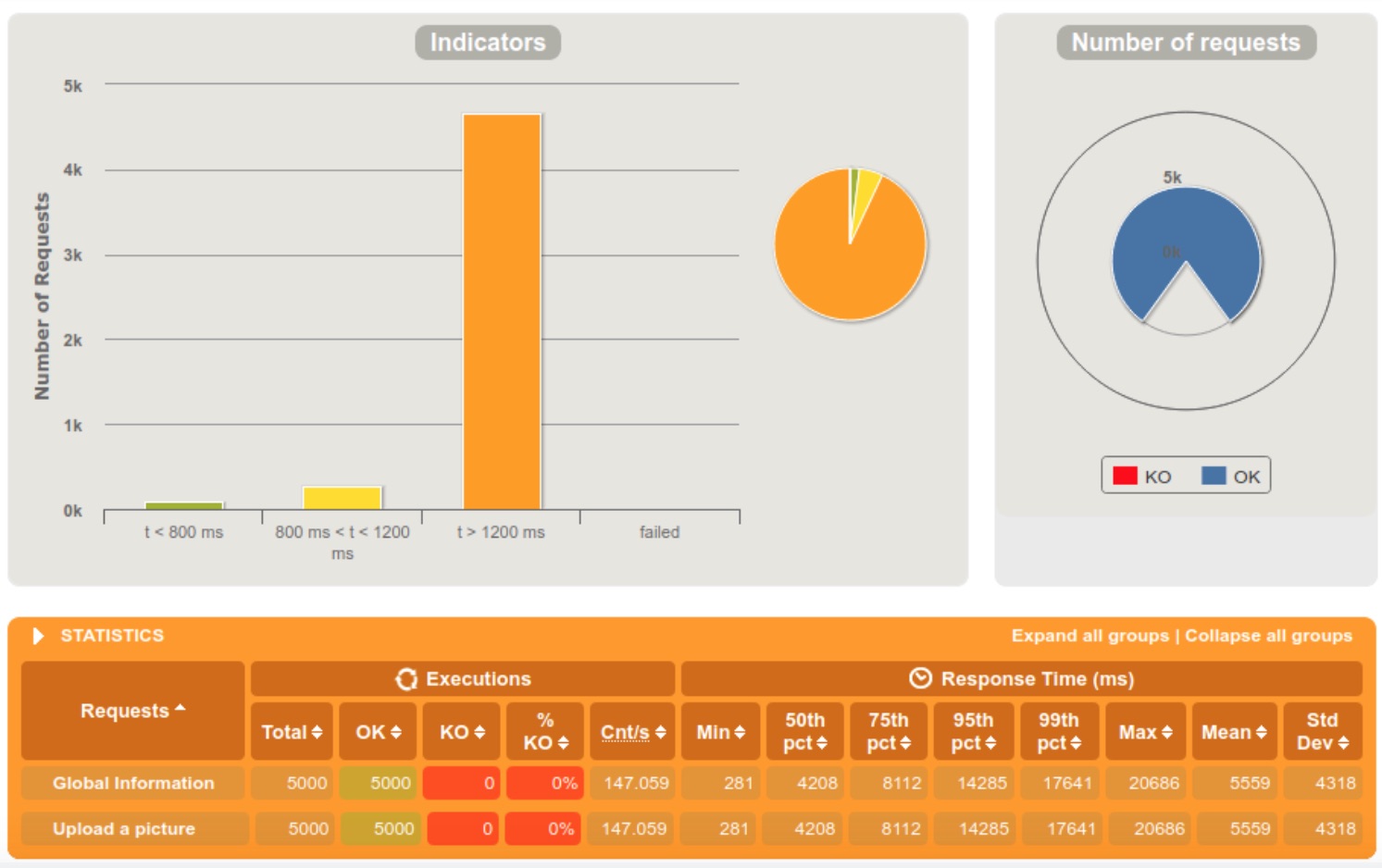
5000 requests within 5 seconds
We clearly notice that the server is doing fine when the requests are diffused in a 60 seconds interval, but starts struggling at 10. When we reached the 5 seconds interval, 13% of the requests were rejected because the server crashed.
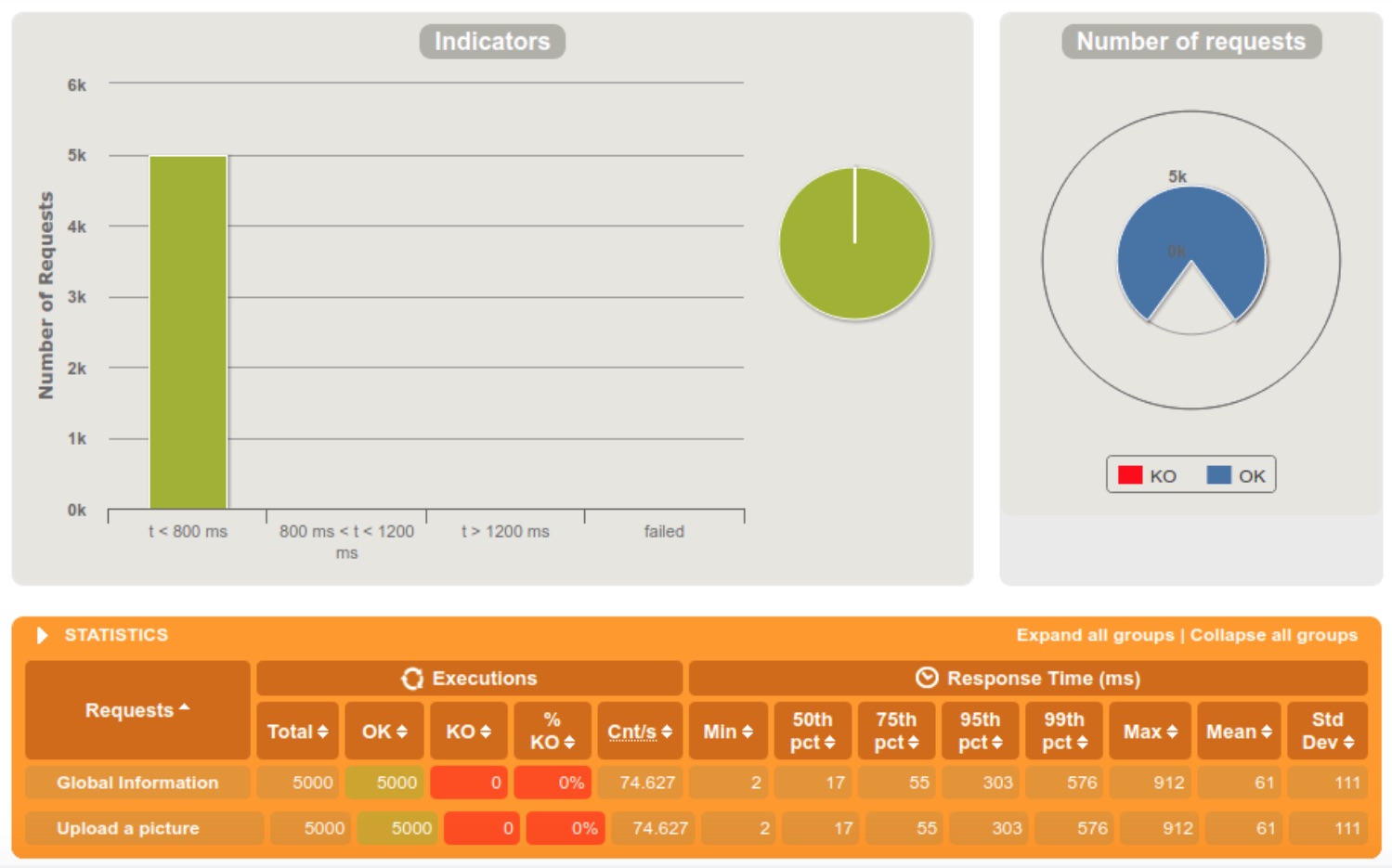
New Media Service performances
5000 requests within 60 seconds
5000 requests within 10 seconds
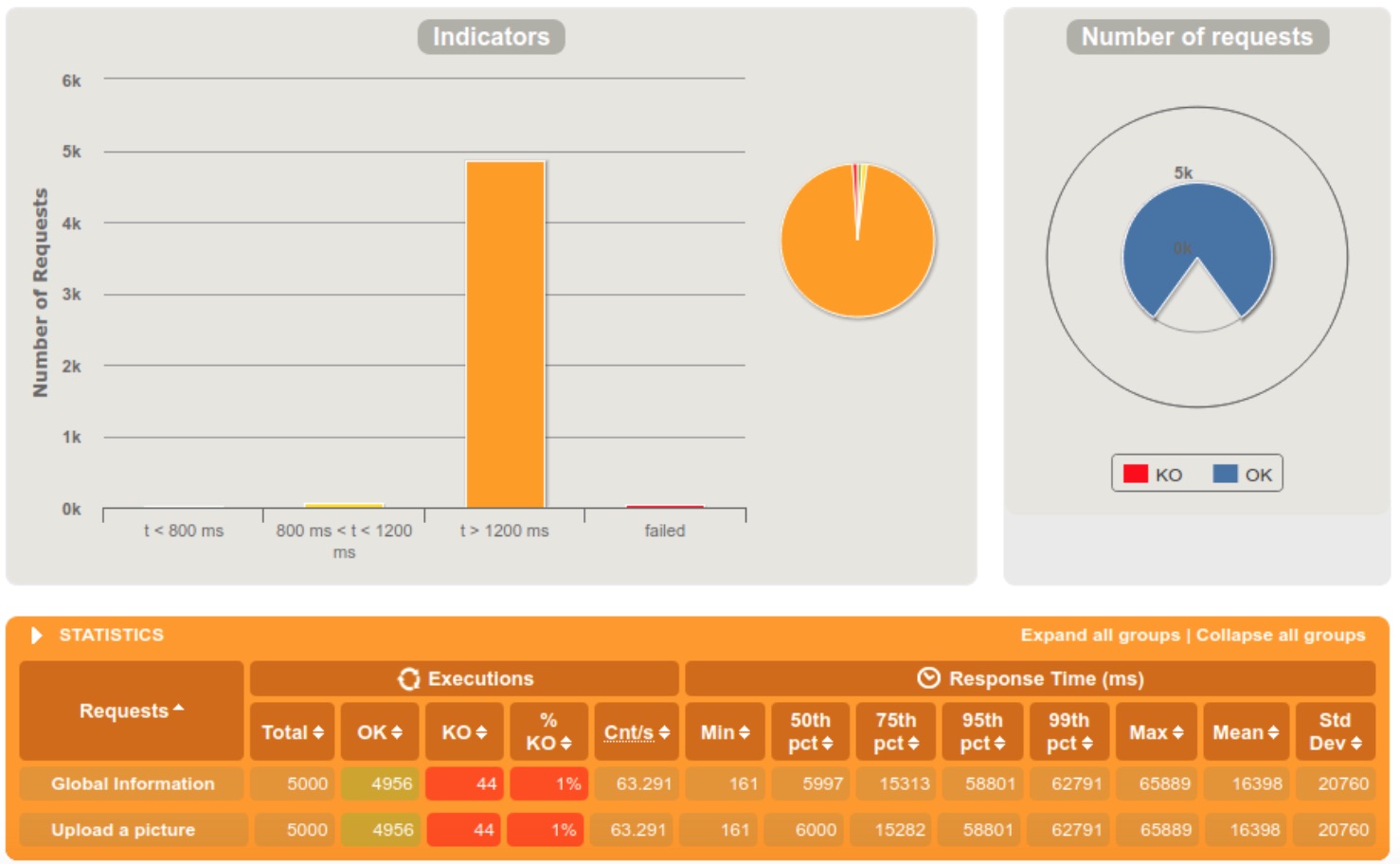
5000 requests within 5 seconds
The first thing that we notice is that the new media service has a much better scalability than the old one, rejecting only 1% of the requests when getting 5000 requests within a 5 seconds tight interval. We can also see a big difference in response times between the old and the new media service.
Conclusion
As Albert Einstein said, “Knowledge is Experience”. As Software Engineers, we sure make choices according to what we think is the best solution at the moment, but after experiencing the reality of production, we can spot some points that can be optimized and enhance even more the performances of our solution, so the best way to evolve is to be able to question yourself about your own solutions, and ask “Am i doing it the best way ? “.
At Yucca Labs, we used to combine Product Line engineering and Service-oriented computing in order to build platforms that evolve well over time along with market changes.
Keeping focused on the product while its functional scope is getting bigger requires a strong ability to provide a relevant design that ease,
The integration of new features
The proper use of technologies
The deployment & integration processes
The testing
The new developers onboarding
Microservices as a design pattern,
Microservices approaches in theory look very promising but they require taking into account shifts and requirements that are very specific to the problem you’re trying to solve in order to be properly implemented.
Microservices require splitting your application into multiple small services that you can deploy and scale individually. Taking advantage of various sets of technologies and languages.
It also helps you perform a faster release and cycle based on very targeted deployments.
The devil of Microservices
Purist approaches end up getting stuck on drawbacks most of the time. The complexity pure microservices techniques introduce are very hard to tackle;
interactions between services rely on network calls that can and will fail.
Debugging a microservices solution can become a nightmare.
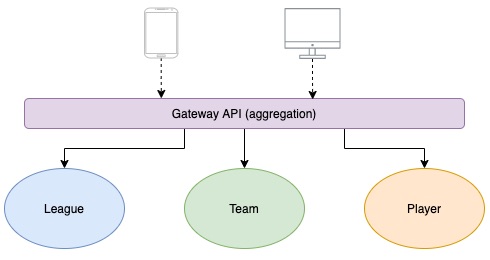
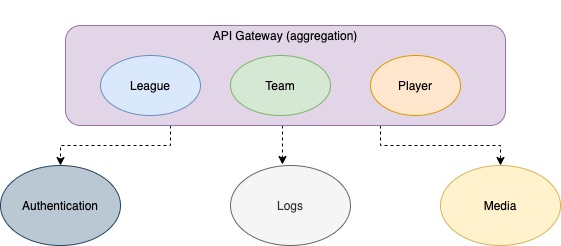
As an example, let’s say we’ve to build a solution to manage a football league. A pure Microservices approach advice us to design 3 well decoupled services as follow,
A dedicated microservices for leagues
One for teams
One for players
And probably an extra microservices that manage the league’s calendar.
Taken separately, these microservices don’t provide functionally consistent data. A league consists of a set of teams and a team mainly contains a number of players. eams
Gathering information on a league or a team consists of loading teams and players.
We always need to aggregate data issues from +1 microservices in order to serve our clients requests.
Each time a microservices evolves you’ll need to upgrade the consumers (clients app).
A Gateway API to aggregate data …
Aggregation here could be performed by a lightweight gateway API put on top of your microservices layer in order to serve the client apps (web or mobile)
We perform at least 3 network calls for every request which could be improved if we rethink the design differently.
Here comes The Hybrid approach …
Why don’t we put the league, team, player within an aggregate service or Gateway API and only externalize services that are independent (security, logs, media files management, … etc)